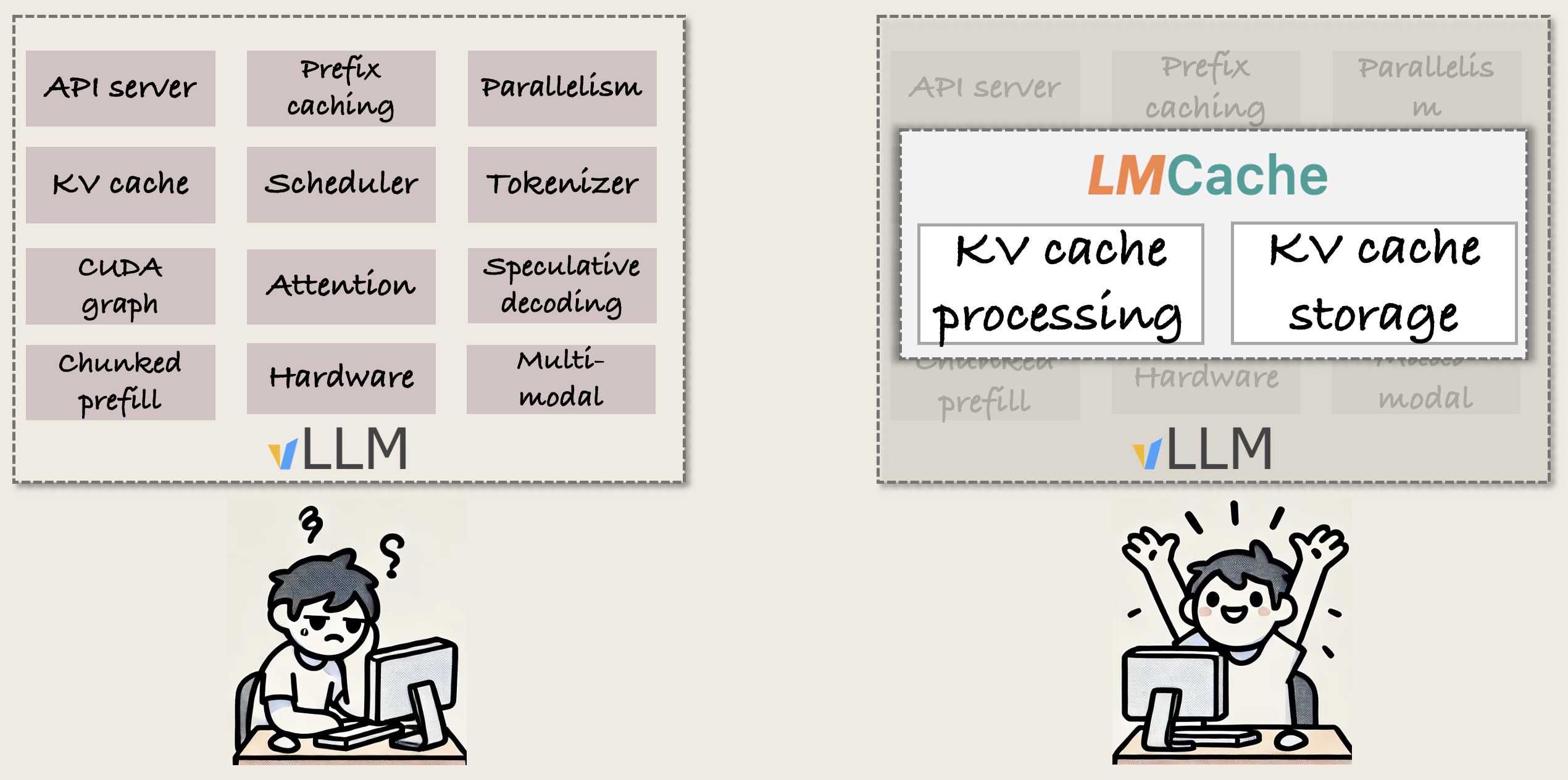
🚀 Building your system on KV cache? Try building it on LMCache!
By using LMCache for your research, you can focus on KV cache management, while we handle all the vLLM integration and compatibility for you.
Here’s why LMCache works as your research testbed:
- Simple codebase, all vLLM functionalities. vLLM has over 200k lines of Python code. LMCache? Just 7k lines, specialized for KV cache, so you get much less code to read and work with, while LMCache handles all the vLLM feature compatibility for you.
- Boost your evaluations with ready-made KV cache research. With implementations of the latest research (think CacheGen and CacheBlend), you’re all set to use them as baselines or show that your system can be used together with them for higher improvements.
- Showcase your impact, fast. Implement in LMCache, and your research is instantly runnable with vLLM. Plus, we have rich demos for you to showcase your system in conference talks or presentations.
Check our codebase and documentations for more information!
Update: we are delighted to see that there are already papers (like Cake) start to use LMCache as their research testbed.