A picture is worth a thousand words:
Executive Summary:
-
vLLM Production Stack, an open-source reference implementation of a cluster-wide, full-stack vLLM serving system, was first released in Jan 2025 by researchers from vLLM and UChicago. Since then, the system has gained popularity and attracted a growing open-source contributor community (check out our previous blog).
-
vLLM Production Stack offers:
- Significantly better performance over other systems in the vLLM ecosystem based on stress tests in real production environments.
- Full-stack features, including K8s-native router, autoscaling, LoRA management, distributed KV sharing, monitoring, fault tolerance, etc. Our next blogs will dive into other features.
- Since real-world performance numbers are not public (which will be a future blog!), today we released a benchmark everyone can test vLLM Production Stack. In particular, it shows that vLLM Production Stack performs 10X faster and more cost-efficient, in prefill-heavy workloads, than the baseline vLLM deployment method as well as AIBrix, another full-stack system recently released in the open-source community. We made public both the benchmark scripts and tutorial.
[vLLM Production Stack Github] | [Get In Touch] | [Slack] | [Linkedin] | [Twitter]
Benchmark setups
Methods:
-
vLLM Production Stack: We use the default settings of vLLM Production Stack (v0.1.0) and set the CPU offloading buffer size (i.e.,
cpuOffloadingBufferSize) to 120 GB per pod. -
AIBrix: For fair comparison, we used the stable release of v0.2.0 with the default setup and set “
VINEYARD_CACHE_CPU_MEM_LIMIT_GB” to 120GB andcacheSpec memoryto 150GB. (120GB per pod) -
K8s+vLLM: As a reference point, we consider a simple K8S deployment with the same vLLM version and helm chart as used in the vLLM Production Stack, albeit without its KV cache and routing optimizations.
Workload: Inspired by our production deployments, we create workloads that emulate a typical chat-bot document analysis workload. By default, each LLM query input has 9K tokens, including a document (roughly a 12-page pdf) as the context and a unique short question, and the LLM output is a short answer of 10 tokens. The context of each query is randomly selected from 70 documents, and to prevent the same document being queried too many times, each document is used as the context in only about 14 LLM inputs.
Faster and higher throughput
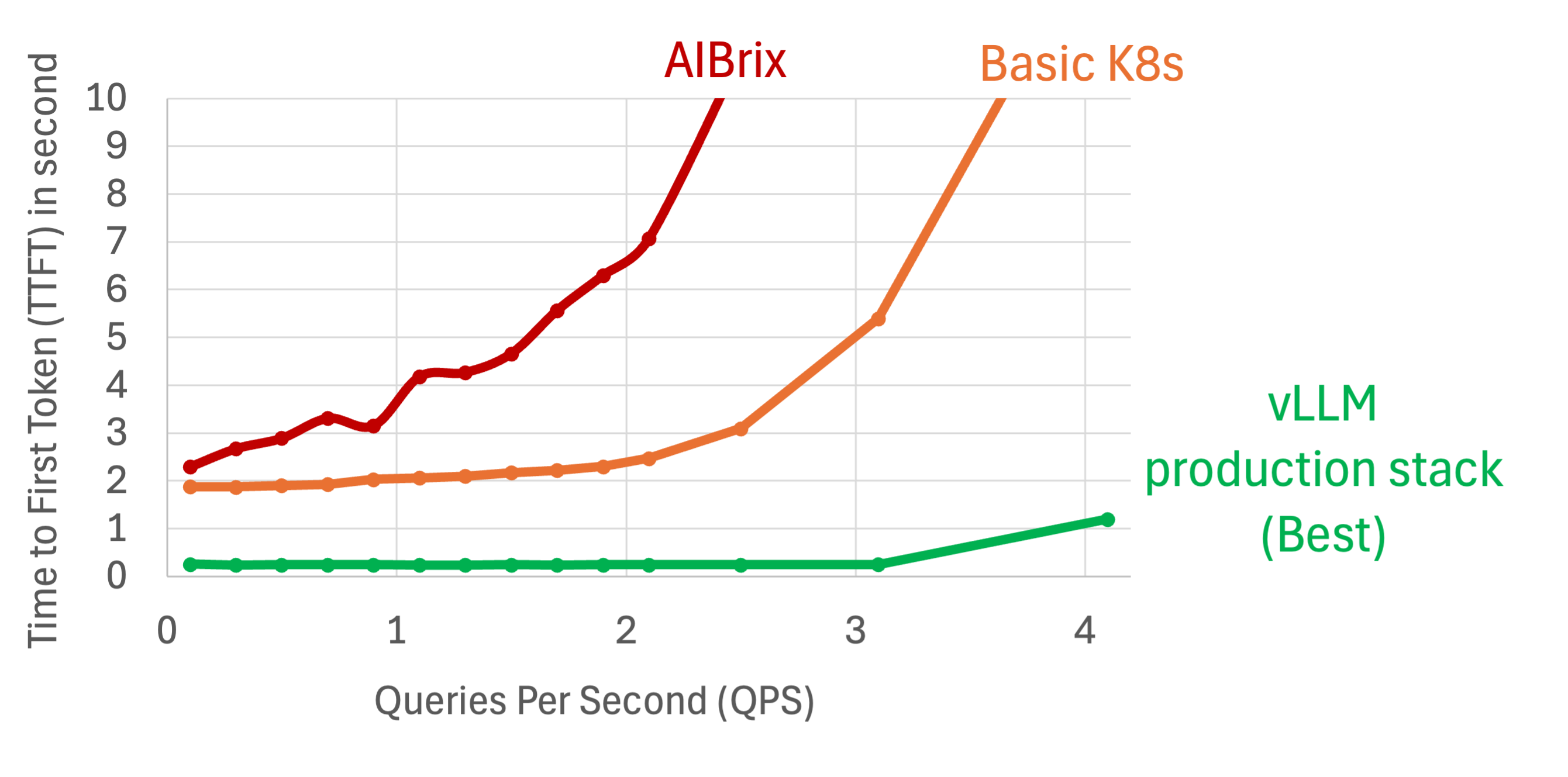
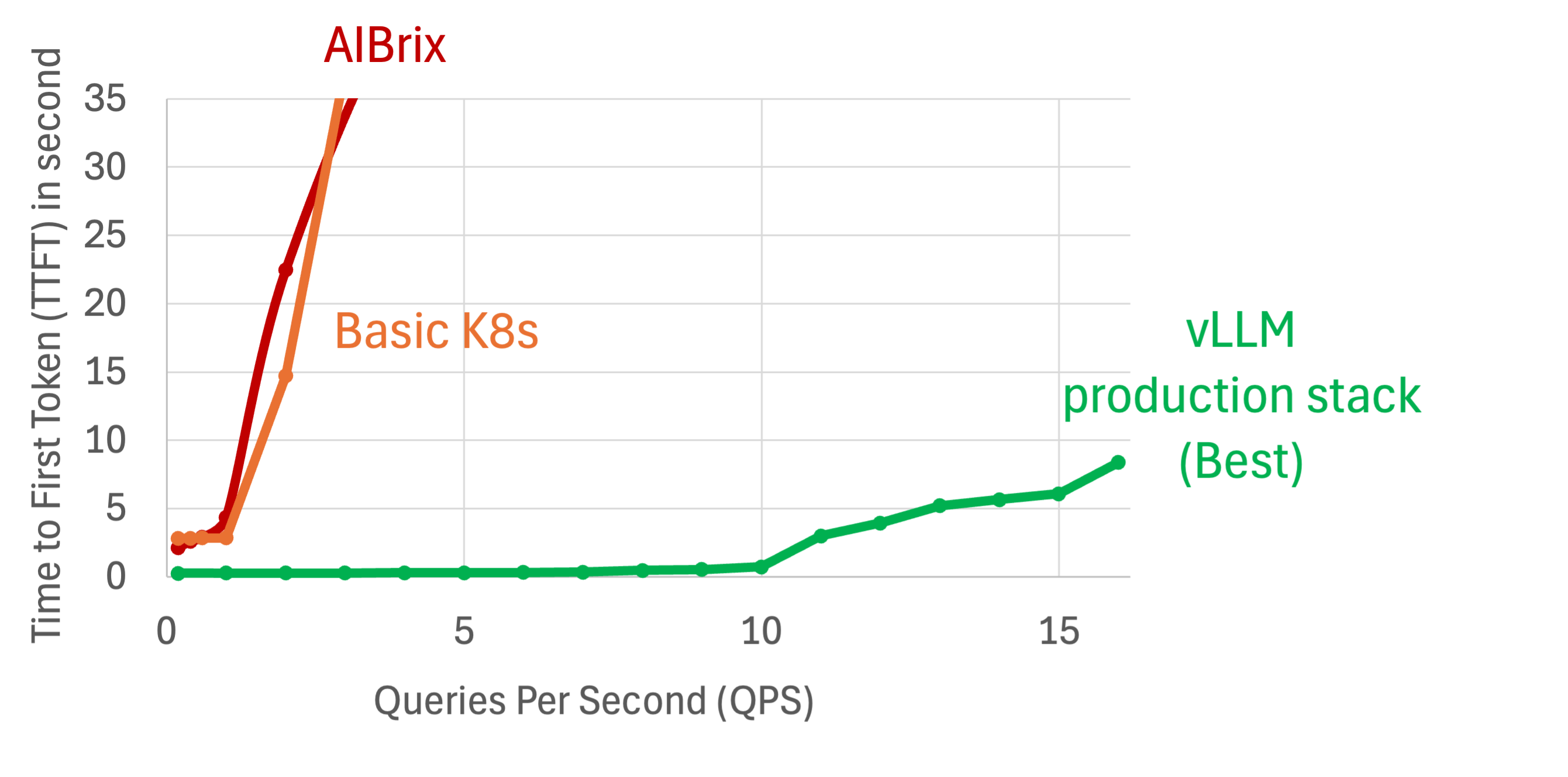
First, we compare the average time-to-first-token (TTFT) delay as a function of queries per second (QPS) for these three solutions:
AIBrix (red line) shows a steep increase in TTFT as QPS rises (i.e., higher loads). This could be attributed to inefficient (pytorch-based) implementation of KV cache offloading and possibly other bottlenecks in other system components.
Naive Kubernetes vLLM (orange line) exhibits more stable performance but still experiences increasing latency with higher query rates due to lack of KV cache optimizations.
vLLM Production Stack (green line), with better KV cache optimization and router design, maintains consistently low TTFT across all QPS levels, demonstrating superior efficiency and scalability. The KV cache component is powered by LMCache, with efficient KV transfer CUDA kernels and dedicated zero-copy design.
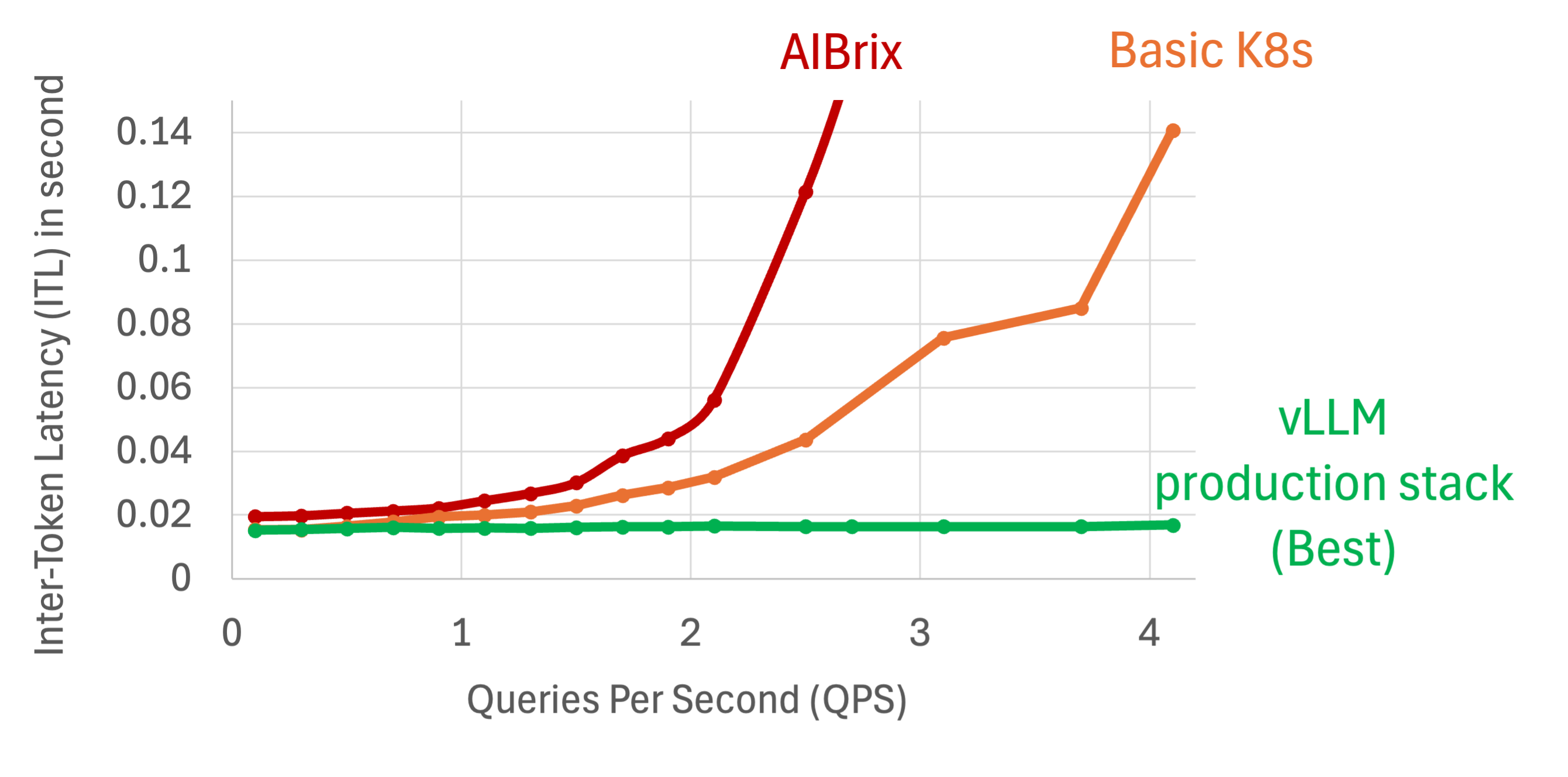
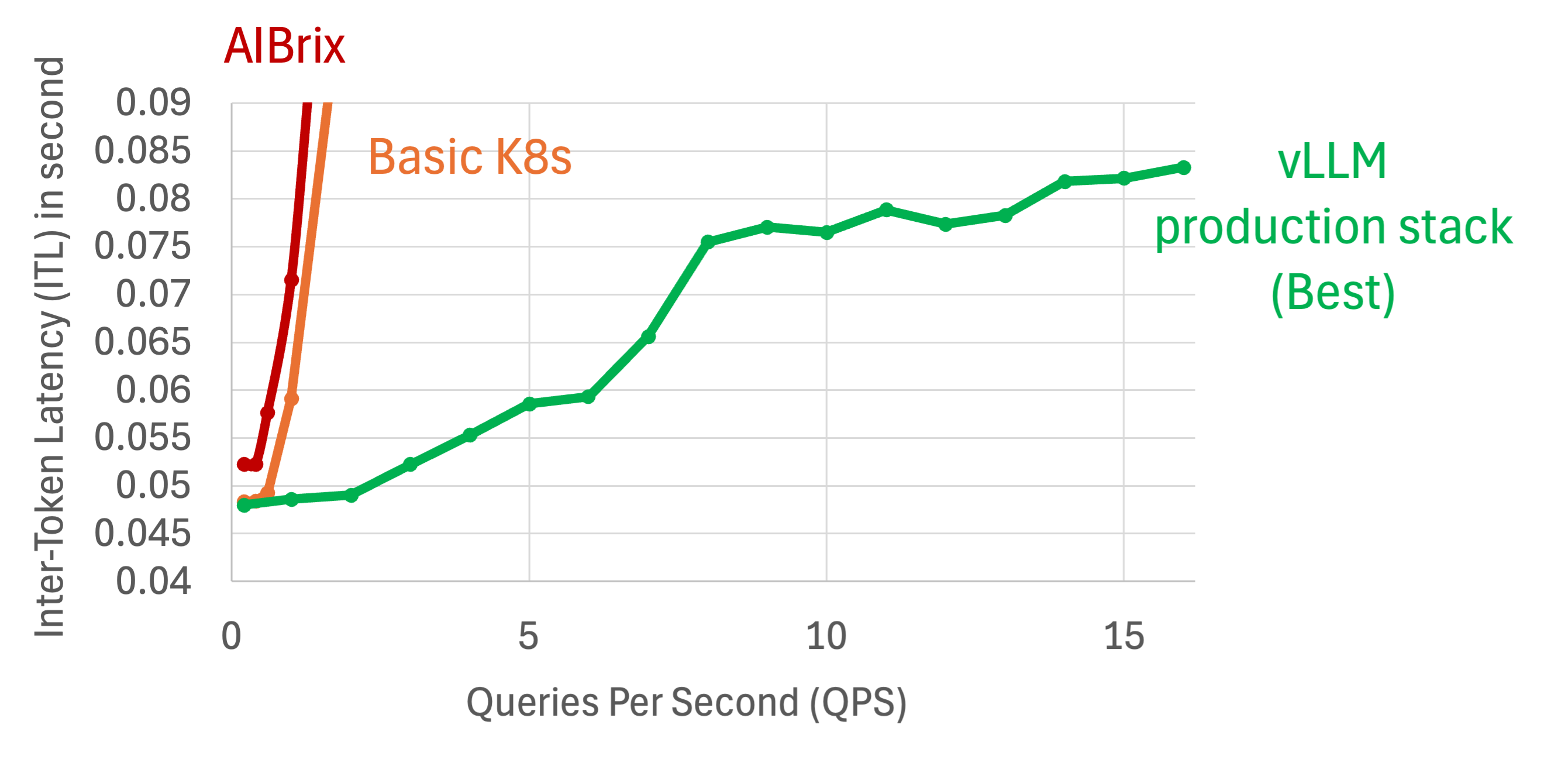
Regarding the inter-token-latency (ITL), we observe a similar pattern that while the ITL of both AIBrix and Naive K8s went up, production stack remains constantly low latency.
In the next set of experiments, we change the number of rounds that user have chat with into 40 rounds per session. Improvement of vLLM Production Stack grows even higher due to the increasing chance of KV cache reuse.
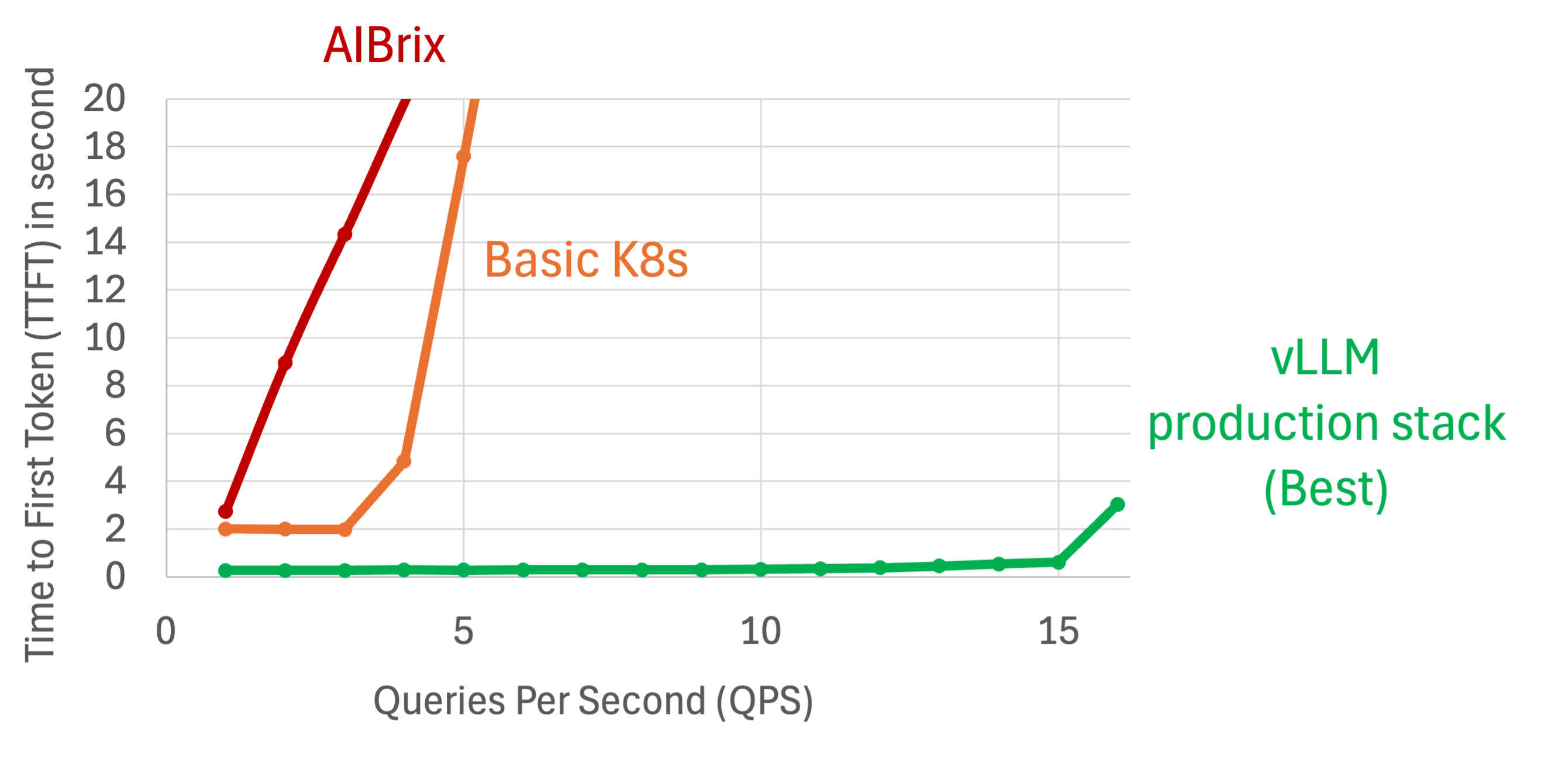
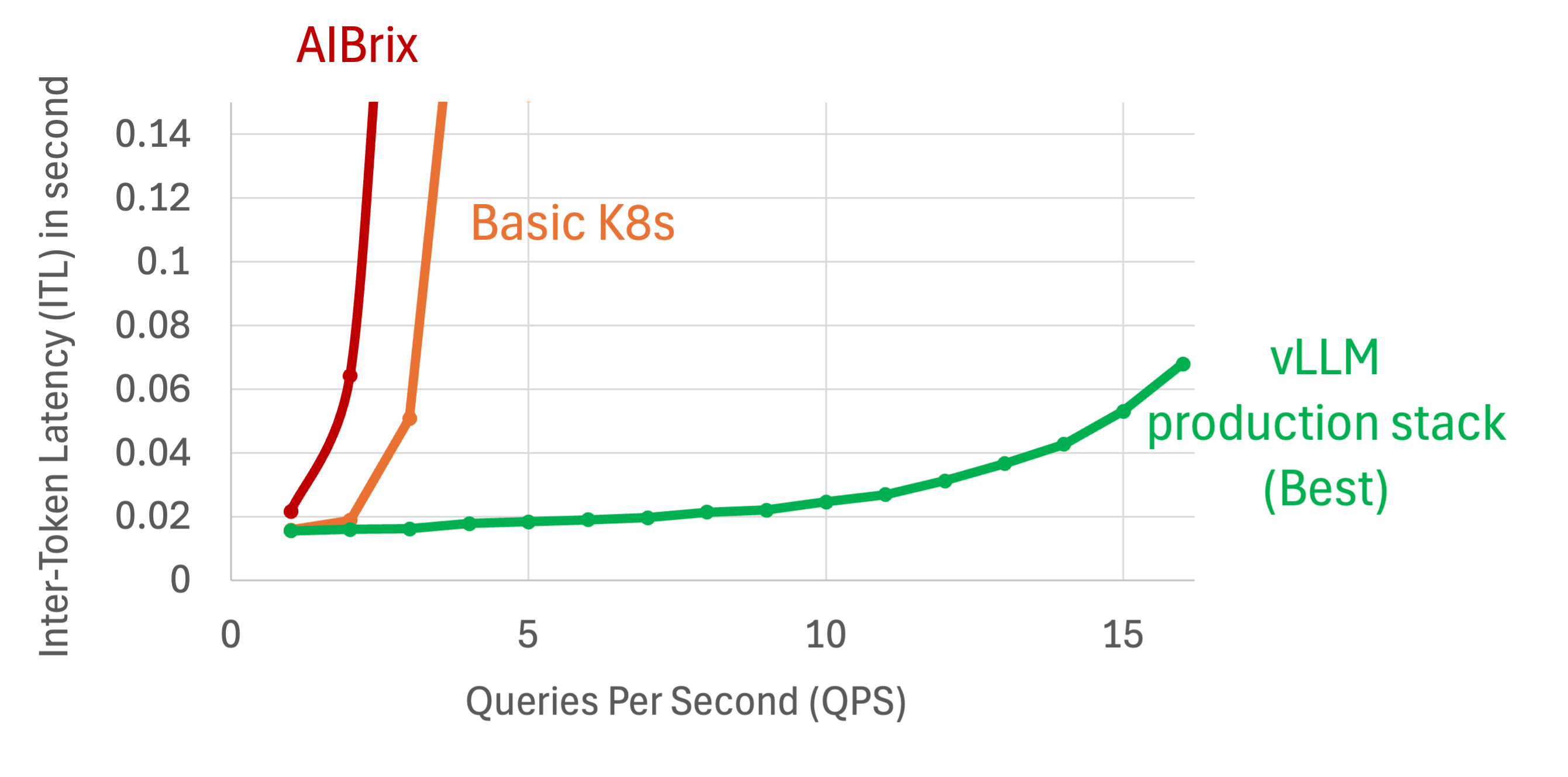
We also tested our performance on bigger models such as Llama-70B. In the following graphs.We emulated running a cluster with 4 nodes, each running Llama-3.1-70B-Instruct with tensor parallelism on 2 A100 GPUs with 80GB. The other specifications per pod stay the same.
We assumed a time period of 70 users participating in 20 rounds of conversations with the LLM. Each requests consists of 9,000 input tokens per user and outputs 10 tokens.
Better availability
High availability is crucial in any production setting. For this reason, We compare the stability of AIBrix and vLLM Production Stack over a period of serving time in the following experiment.
We run each deployment for a 400-second period.


The AIBrix router availability graph shows frequent downtime where the router becomes unavailable at multiple points during the test and requires manually restarting the port forwarding for the service to come back alive.
On the other hand, vLLM Production Stack router availability graph (bottom) demonstrates 100% uptime and with no interruptions throughout the same period.
Concluding Words
While benchmarking doesn’t show the full picture, we hope this blog shows that open-source is not necessarily worse than the industry solution, but could also be 10X better.
Born out of an academic collaboration between vLLM (Berkeley) and LMCache Lab (UChicago), vLLM Production Stack features the most advanced built-in KV-cache optimizations and an upstream support of the latest vLLM releases.
As an OPEN framework, vLLM Production Stack uses helm and Python interface for ease of use and modification. We have received contributions from the community to add more K8S native support, including Envoy Endpoint, dynamic Lora Pool, among others.
We also welcome more benchmarks on different workloads and other serving frameworks. Contact us in the #production-stack channel or LMCache slack today to discuss the future steps!
Join us to build a future where every application can harness the power of LLM inference—reliably, at scale, and without breaking a sweat.
Happy deploying!
Contacts:
- Github: https://github.com/vllm-project/production-stack
- Chat with the Developers Interest Form
- vLLM Production-Stack channel
- LMCache slack