TL;DR: The latest LMCache release plugs seamlessly into vLLM’s new multimodal stack. By hashing image-side tokens (mm_hashes) and caching their key-value (KV) pairs, LMCache reuses vision embeddings across requests—slashing time-to-first-token and GPU memory for visual-LLMs.
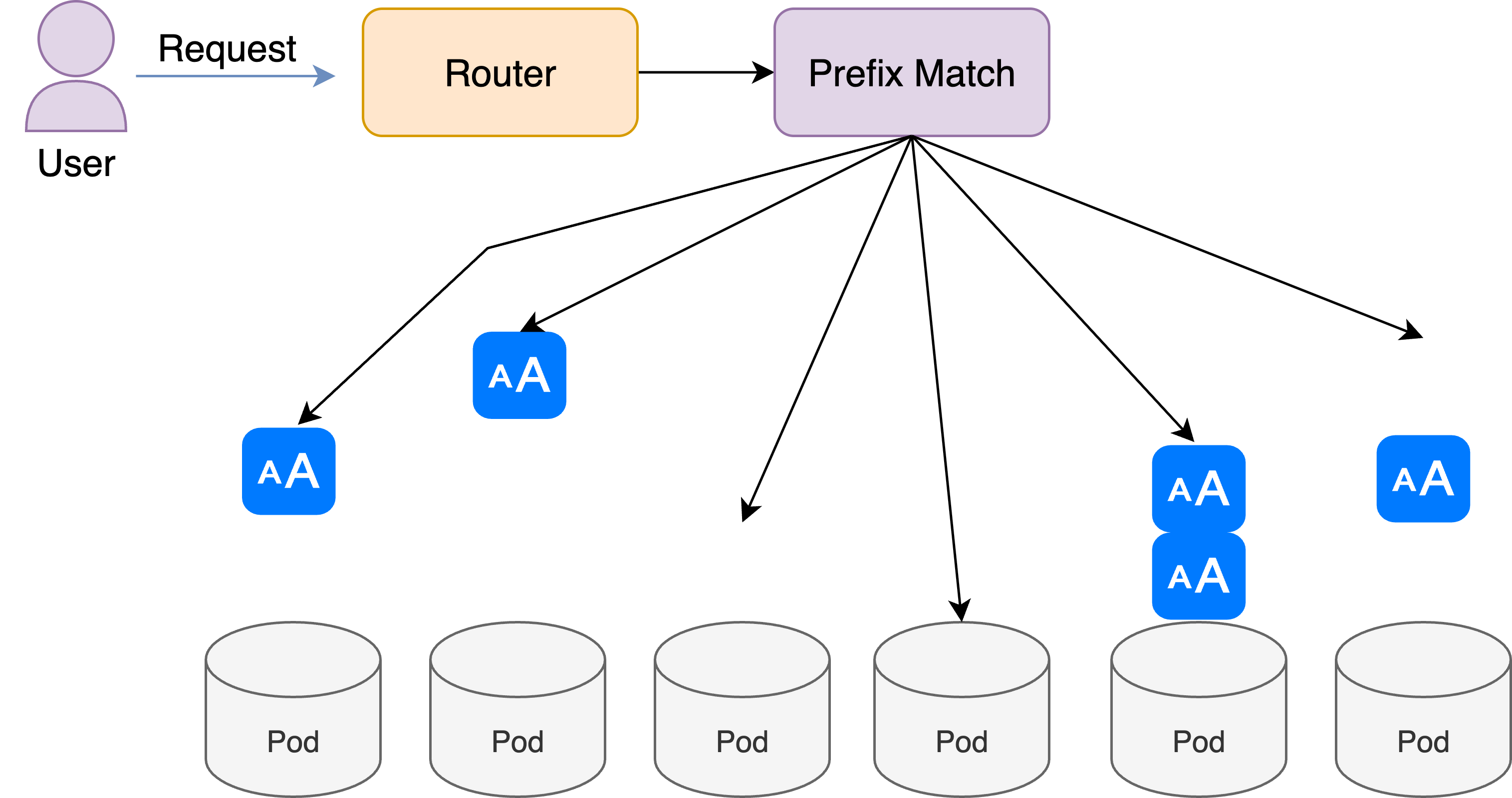
LMCache's multimodal caching architecture
Summary — Why This Matters
Multimodal large language models (MLLMs) multiply KV-cache traffic: every image can add thousands of “vision tokens.” Without reuse, identical pictures force the GPU to re-encode vision features for each query. LMCache 0.3.1 PR #882 adds a hash-based lookup so repeated images hit the cache instead of the GPU pipeline.
In an example run with Qwen-VL-2B:
| Query | Total tokens | KV hits | Hit rate |
|---|---|---|---|
| First image | 16 178 | 0 | 0% |
| Same image (2 nd) | 16 178 | 16 177 | ~100% |
| New image (3 rd) | 4 669 | 0 | 0% |
The second request streamed in ~1 s vs. ~18 s cold-start, showing near-instant reuse.
1 | Introduction — How vLLM Handles Multimodality
In vLLM V1, the input contains a multi_modal_data field besides the prompt data. In the prompt of the input, vision inputs are tokenised by a vision encoder → projector and spliced into the text sequence as placeholder ranges.
For each image it also emits a 16-byte hex digest (mm_hash) that uniquely identifies the visual content.
2 | The Bottleneck Before the Update
Since the prompts contain placeholder tokens for inputted images, given the same prompt but two different images, the prompt prefix matching algorithm will still reuse the KV cache of the images and prompt despite that the images do not match. This error can cause weird behavior when users uploaded different images but the text prompts following are similar. This can potentially cause privacy issues if enabled since other users will be able to access the KV cache of the images other people uploaded.
Thus, the multimodal functionality were not compatible with the advanced offloading capabilities that LMCache provide.
3 | How LMCache Enables Multimodal Caching
In this most recent update, LMCache team member, Shaoting Feng, fixed problem by adding these three key components below:
apply_mm_hashes_to_token_ids()overwrites dummy vision-token IDs with a 16-bit hash (cheap Torch slice) so that the placeholders tokens used in computation are replaced with real token during cache management phase.RequestTrackernow storesmm_hashes+ positions, so every KV lookup/insert sees the complete true hash behind the image + prompt pair.- On cache store/retrieve, LMCache will use those hashed IDs with the original logic without the need to add special path.
As a result, identical images map to identical token sequences, and KV reuse “just works” in both storage and P2P transport modes.
4 | Performance Gains in Practice
Early integration tests on Qwen-VL-2B and DeepSeek-VL2-Small show:
- ~100% hit rate for repeated images (table above) → zero GPU vision passes.
- End-to-end latency trimmed from tens of seconds to ≈1 s for second views.
- KV bandwidth drops proportionally, freeing GPU memory for larger batches—on text-only workloads LMCache already yields 3-10× TTFT speed-ups; the same economics now apply to vision prompts.
5 | Simple Demo
# 1. launch vLLM with LMCache connector
vllm serve Qwen/Qwen2-VL-2B-Instruct \
--kv-transfer-config '{"kv_connector":"LMCacheConnectorV1","kv_role":"kv_both"}' \
--no-enable-prefix-caching --enforce-eager
# 2. POST an image prompt twice – watch the logs
curl -X POST http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" \
-d @first_image.json
curl -X POST http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" \
-d @first_image.json # instant response, log shows ~16k KV hits
Replace the JSON with any Hugging Face MLLM prompt syntax; identical images will hit the cache automatically.
Join the LMCache Ecosystem
LMCache is rapidly expanding its integration footprint.
We’re actively seeking partnerships with LLM inference frameworks and cloud providers interested in:
- KV cache optimization
- Distributed inference pipelines
- High-efficiency on-prem or VPC-based deployments
Let’s make AI infrastructure faster, cheaper, and smarter—together.