TL;DR: LLMs are rapidly becoming the dominant workload in enterprise AI. As more applications rely on real-time generation, inference performance — measured in speed, cost, and reliability — becomes the key bottleneck. Today, the industry focuses primarily on speeding up inference engines like vLLM, SGLang, and TensorRT. But in doing so, we’re overlooking a much larger optimization frontier: the system above and across the engines.
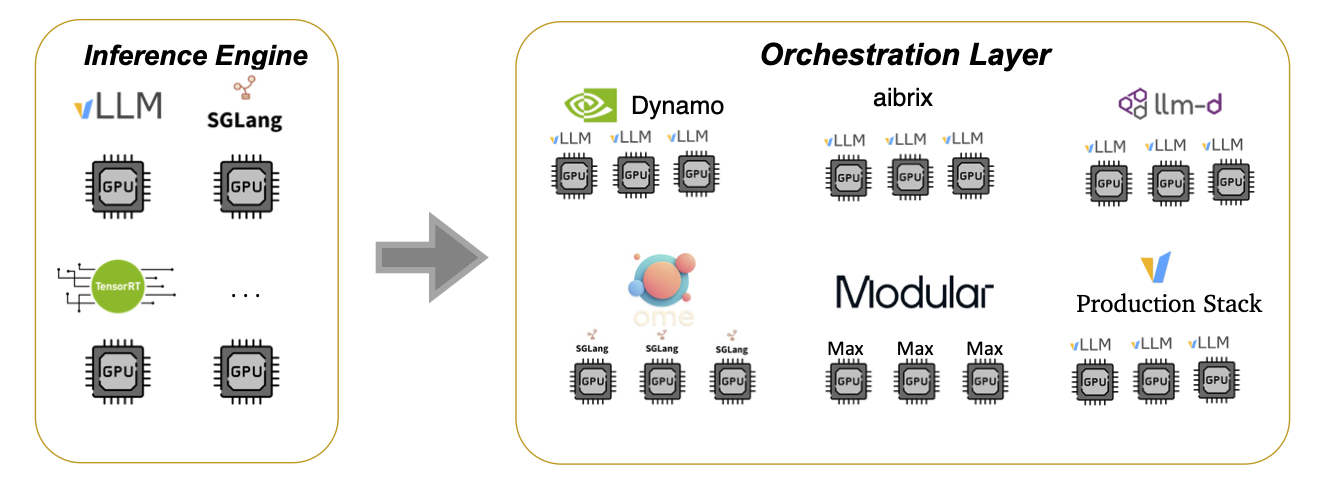
LLM Inference beyond from Inference Engine
The Status Quo: Replicating Inference Engines at Scale
LLM inference systems today are built with two major components:
- Inference Engines — which optimize inference for a single model instance.
- Orchestration Layer — which uses tools like Kubernetes to replicate these engines for horizontal scaling.
This “engine-centric” mindset assumes that most performance gains come from within the engine. Orchestration is treated as a thin, mostly stateless layer — simply spin up more replicas to boost throughput.
This model powers open-source systems like:
- vLLM Production Stack mainly maintained by LMCache Lab
- RedHat’s llm-d and KServe
- Nvidia’s AI Dynamo
- ByteDance’s AIBrix
- Modular
- SGLang OME and similar inference platforms
These stacks scale out well, but they hit a ceiling when deeper system-level optimizations are needed.
The New Frontier: LLM-Native Optimization Beyond the Engine
Real performance gains lie in orchestrating across engines — by sharing state, reusing computation, and optimizing globally. For example:
- Dynamic prefill/decode disaggregation
- Optimized KV cache sharing across sessions (transmission, compression)
- Online KV cache updates (blending, editing, translation)
- Sleep-time compute outside the request path
- Query migration and cross-agent pipelining
These optimizations require stateful coordination and intelligent scheduling — things a vanilla Kubernetes setup can’t easily support. That is where innovations at the orchestration level can bring significant performance benefits.
Kubernetes Alone Isn’t the Problem — But It’s Not Enough
Let’s be clear: we’re not saying Kubernetes is useless. It’s an essential part of the modern software infrastructure. What we’re saying is this — using Kubernetes alone for LLM inference orchestration limits what’s possible.
Here’s why existing K8s-based open-source systems fall short:
Stateless Replicas Only
Kubernetes treats all pods as stateless, homogeneous units. But LLM workloads rely on shared, stateful components like KV cache and intermediate tool-call state. Many optimizations in the LLM era require state to persist and be shared across requests and replicas — something Kubernetes doesn’t natively support.
Request-Driven Execution Only
Optimizations like cache compression, sleep-time prefetching, or background blending need computation outside the critical request path. But Kubernetes-based orchestrators are built around request-response models — there’s no clean way to schedule or interrupt background jobs alongside the mainstream inference job.
Poor Fit for LLM-Specific Logic
Inference-specific scheduling (e.g., prioritizing latency-sensitive vs. background jobs) is hard to express in existing orchestration frameworks. Worse, most systems are written in Go or Rust — languages that aren’t ideal for fast prototyping of tensor-intensive, Pythonic workloads.
Difficult to Deploy & Operate
Kubernetes-native inference stacks are significantly harder to deploy and operate compared to API or dedicated endpoint-based solutions like OpenAI, Claude, Fireworks, or Together AI. Even teams with infra expertise struggle to keep up as more optimizations and hacks are layered into already complex systems.
Bottom line: the more we push the frontier of inference optimization, the more Kubernetes-only architectures become a bottleneck.
What We Need: An LLM-Native Orchestrater
To support the next generation of inference workloads, we need a purpose-built orchestrator for LLMs. It should:
- Support tensor-optimized communication and state sharing (for KV cache reuse, migration, pipelining)
- Enable interruptible background jobs (for compression, blending, and non-request workloads)
- Schedule across real-time and background jobs with awareness of latency, compute usage, and dependencies
- Be easy to deploy and operate, even for teams without deep expertise in infra
This doesn’t replace Kubernetes — it complements it. Kubernetes can still manage container lifecycles, node scaling, and fleet management. But inference workloads themselves need orchestration logic that understands LLM-specific patterns.
What’s Next
We’ve built an LLM-native orchestration solution to address these needs — supporting powerful system-level optimizations without sacrificing usability. In our next post, we’ll share details about its architecture, performance, and real-world deployment.
Stay tuned.
Links
- LMCache Github: https://github.com/LMCache/LMCache
- Chat with the Developers Interest Form
- LMCache slack
- vLLM Production-Stack channel