TL;DR: LLMs are transforming every product and service—from chatbots and copilots to intelligent document search and enterprise workflows. But running LLMs in production is still painfully slow, prohibitively expensive, and complex to manage. That changes today.
We’re excited to announce the launch of LMIgnite — the first one-click deployable high-performance LLM inference backend for Conversational and Long-Document AI. Built on the powerful combination of vLLM Production Stack and LMCache, LMIgnite is purpose-built to accelerate, scale, and simplify LLM serving, especially for conversational AI (e.g., chatbots) or long-document AI (e.g., document analysis).
Why LLM Inference Needs a Rethink
While training LLMs captures headlines, inference is where the real bottlenecks lie:
- Slow: Long context windows and complex reasoning increase latency.
- Expensive: Inference cost scales with every input and output token—unlike training, which is a one-time cost.
- Hard to self-host: Current open-source tools require stitching together multiple components and require experts to do so.
- Lack of support for latest models: The rapid release of new models (~1 every 4 days in 2025!) makes support brittle.
It’s clear we need an inference stack that is
- Fast and cost-efficient
- Dead simple to deploy
- Self-host on any GPU cloud or on-prem servers
Meet LMIgnite
LMIgnite is the first complete solution that hits all four marks.

LMIgnite Comparison with Previous Methdos
It brings together:
- LMCache: A research-driven KV cache backend and transfer layer that delivers cutting-edge performance.
- vLLM Production Stack: A robust, scalable, and Kubernetes-native system for running distributed vLLM clusters with LLM workload intelligent routing.
- One-click Deployment: No infrastructure headaches. Launch in minutes via SkyPilot or our custom UI.
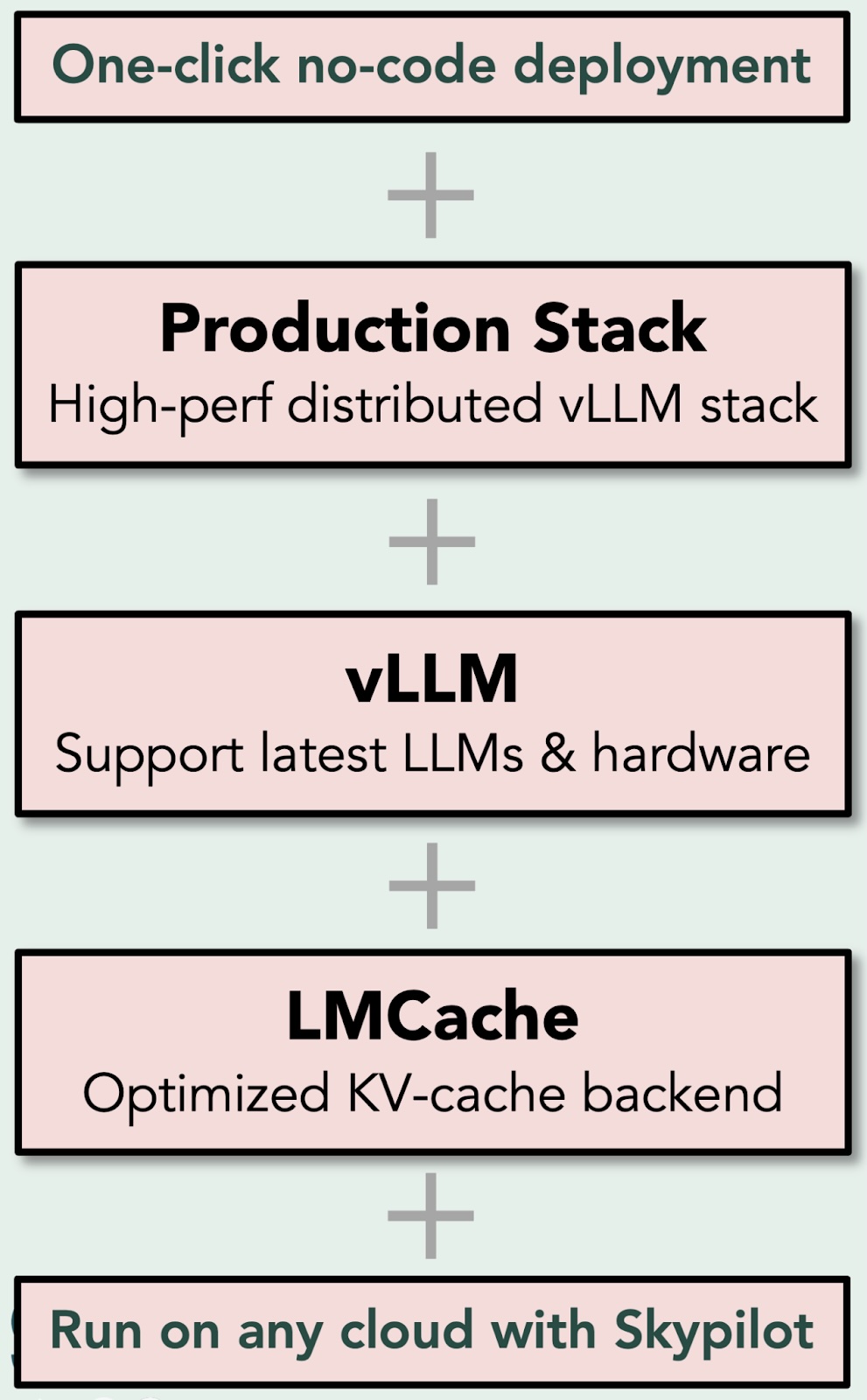
LMIgnite Overview
Unmatched Performance, Backed by Research
LMIgnite delivers up to 10× speedup and cost savings compared to both open-source and commercial inference solutions like Dynamo, RayServe, Fireworks, and DeepInfra.
The secret? KV cache-native optimizations proven in top research venues:
- Highly optimized KV cache loading (LMCache): Efficiently stores and loads KV cache between CPU and GPU, minimizing memory bottlenecks.
- KV Cache Compression (SIGCOMM ‘24): Shares cache across nodes with minimal bandwidth, enabling distributed efficiency.
- KV Cache Blending (EuroSys ‘25 Best Paper): Seamlessly merges previous document queries for smarter, more accurate retrieval-augmented generation (RAG).
- KV Cache-Aware Routing (vLLM Production Stack): Intelligently routes requests to reduce redundant prefill computation and maximize cache reuse.
- NIXL-based Disaggregation (LMCache): Unlocks flexible compute and memory coordination across the cluster, decoupling storage and compute for maximum scalability.
Together, these innovations let LMIgnite reuse KV cache instead of reprocessing raw tokens—just as model weights capture knowledge after training, the cache captures and reuses computation for blazing-fast inference.
Deploy Anywhere, Effortlessly
LMIgnite runs on any cloud provider (GCP, Lambda, etc.) via SkyPilot with:
- 1-click cluster deployment
- 1-click LLM deployment
- Performance dashboard
- Full observability
- vLLM upstream compatibility
Wanna Get Started Now?
Demo:
LMIgnite Demo Video
Who Is LMIgnite For?
- Developers & Startups building chat, RAG, or copilot apps
- Enterprises looking to self-host models like Llama, DeepSeek, or Mistral
- Infra teams tired of debugging glue code
- Researchers optimizing inference at scale
LMIgnite is open source. Production-ready. And just one click away.
Contacts
- LMCache Github: https://github.com/LMCache/LMCache
- Chat with the Developers Interest Form
- LMCache slack
- vLLM Production-Stack channel