TL;DR: 🚀 LMCache Lab cuts decoding latency for code/text editing by 60% with speculative decoding! ⚡
You might know LMCache Lab for our KV cache optimizations that make LLM prefilling a breeze. But that’s not all! We’re now focused on speeding up decoding too—so your LLM agents can generate new content even faster. In other words: you can save on your LLM serving bills by renting fewer machines for the same amount of work. 🎉💸
How do we make decoding fast? 🤔
We discovered that speculative decoding can reduce token generation time (measured as time-per-output-token) by 60% for both code and text editing tasks. Why? Editing often reuses word pairs that already exist, and speculative decoding takes advantage of this to accelerate the process. Rest assured—speculative decoding won’t change your outputs, just how quickly you get them!
Benchmarks 📊
We tested speculative decoding by editing docstrings in Python files from the popular open-source project vLLM. Here’s what we saw:
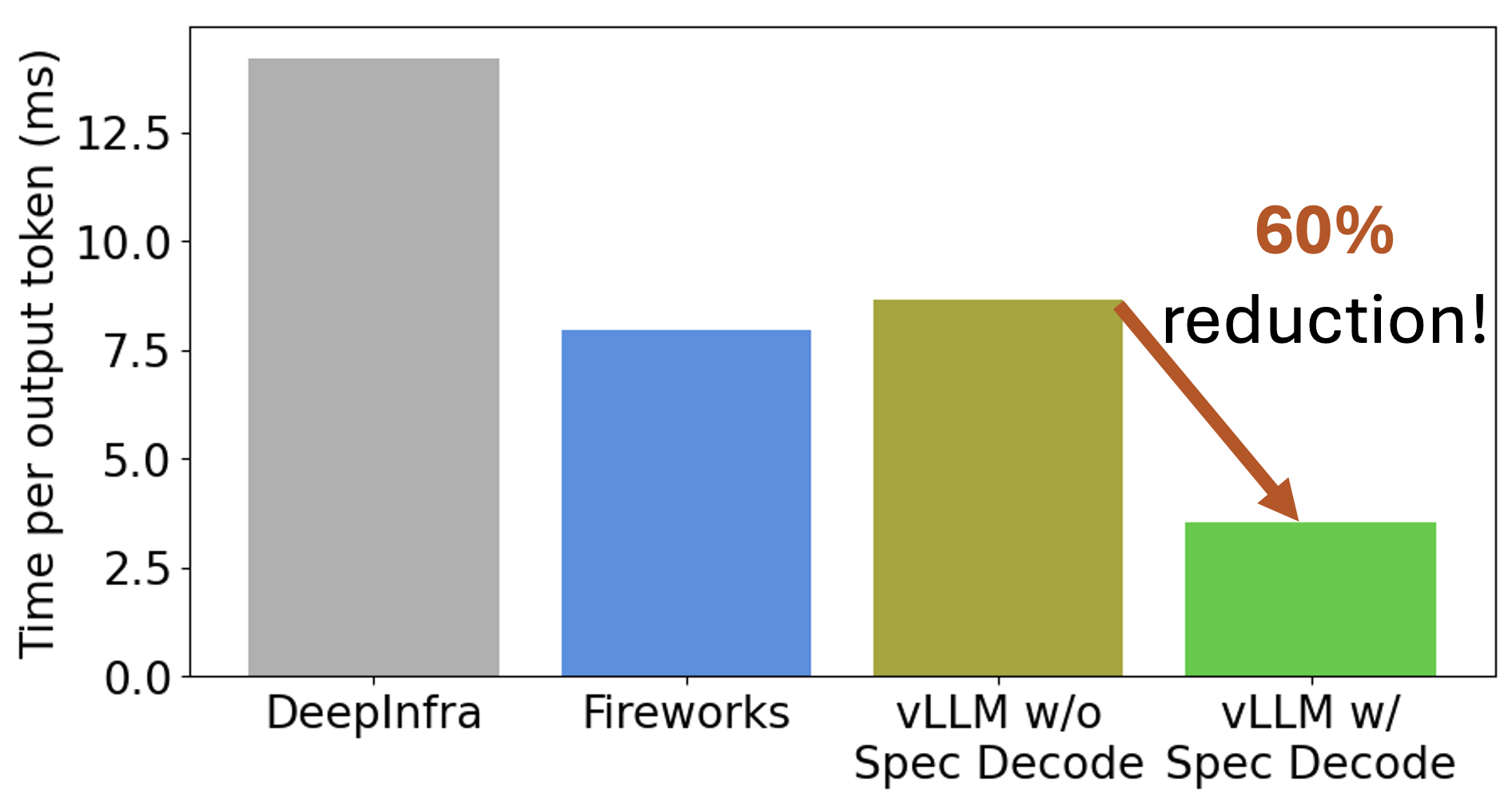
Deploying Llama 3.1 8B Instruct on a single H100 and running at 3 queries per second (QPS=3), time per output token dropped by 2.5x with speculative decoding!
Implementation 🛠️
And we’re not stopping here! We did notice the speed boost drops a bit when requests get bursty:
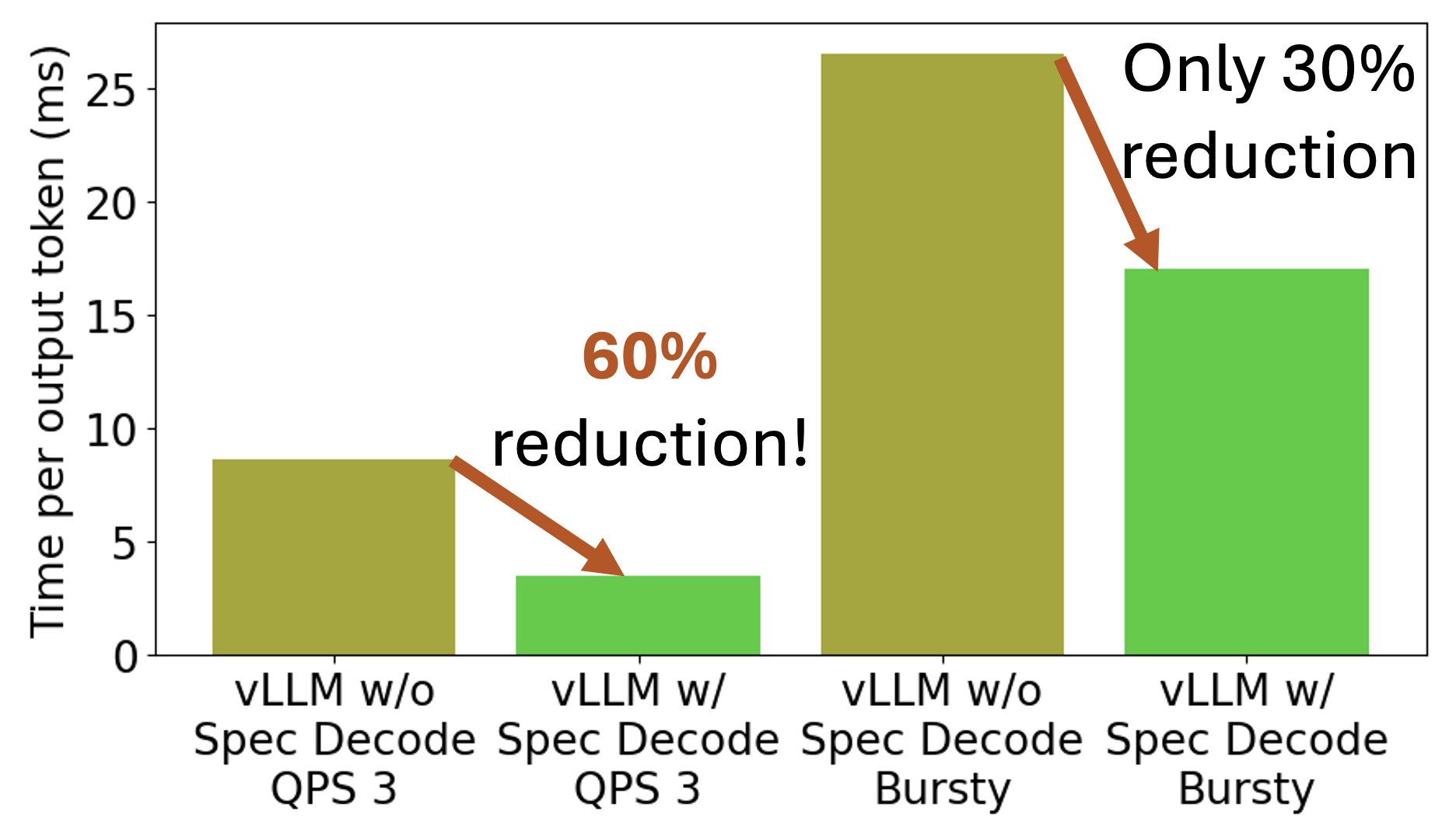
So, we’re launching speculative decoding as an early access feature—and we’ll keep working on automated solutions to help you get the most out of it.
Wanna try it out? 🙌
Curious to give it a spin in your own app? Our new one-click deployment platform, LMIgnite, lets you try the latest LMCache Lab techniques effortlessly, using your own cloud machines or local cluster! Sign up here to enjoy the speedup and cost savings, and get notified as soon as speculative decoding is ready for you in LMIgnite!