TL;DR: 🚀 CacheGen lets you store KV caches on disk or AWS S3 and load them way faster than recomputing! It compresses your KV cache up to 3× smaller than quantization so that you can load your KV cache blazingly fast while keeping response quality high. Stop wasting compute — use CacheGen to fully utilize your storage and get instant first-token speedup!
CacheGen reduces KV cache loading time from disk.
Why CacheGen?
Modern LLMs use long contexts, but reprocessing these every time is slow and resource-intensive.
While engines like vLLM (and LMCache) can cache contexts in GPU and CPU memory, that’s not enough for many chat or agent workloads—hot contexts are a lot and GPU & CPU memory alone are not enough — we need to use disk and even S3 to store all KV caches.
However, storing and loading KV caches from disk or S3 is usually even slower than recomputing them from text!
CacheGen fixes this: you can persist KV caches to any storage (S3, disk, etc.) and reload them much faster than a fresh prefill. Perfect for keeping valuable context for all your users and agents—without the cold-start penalty.
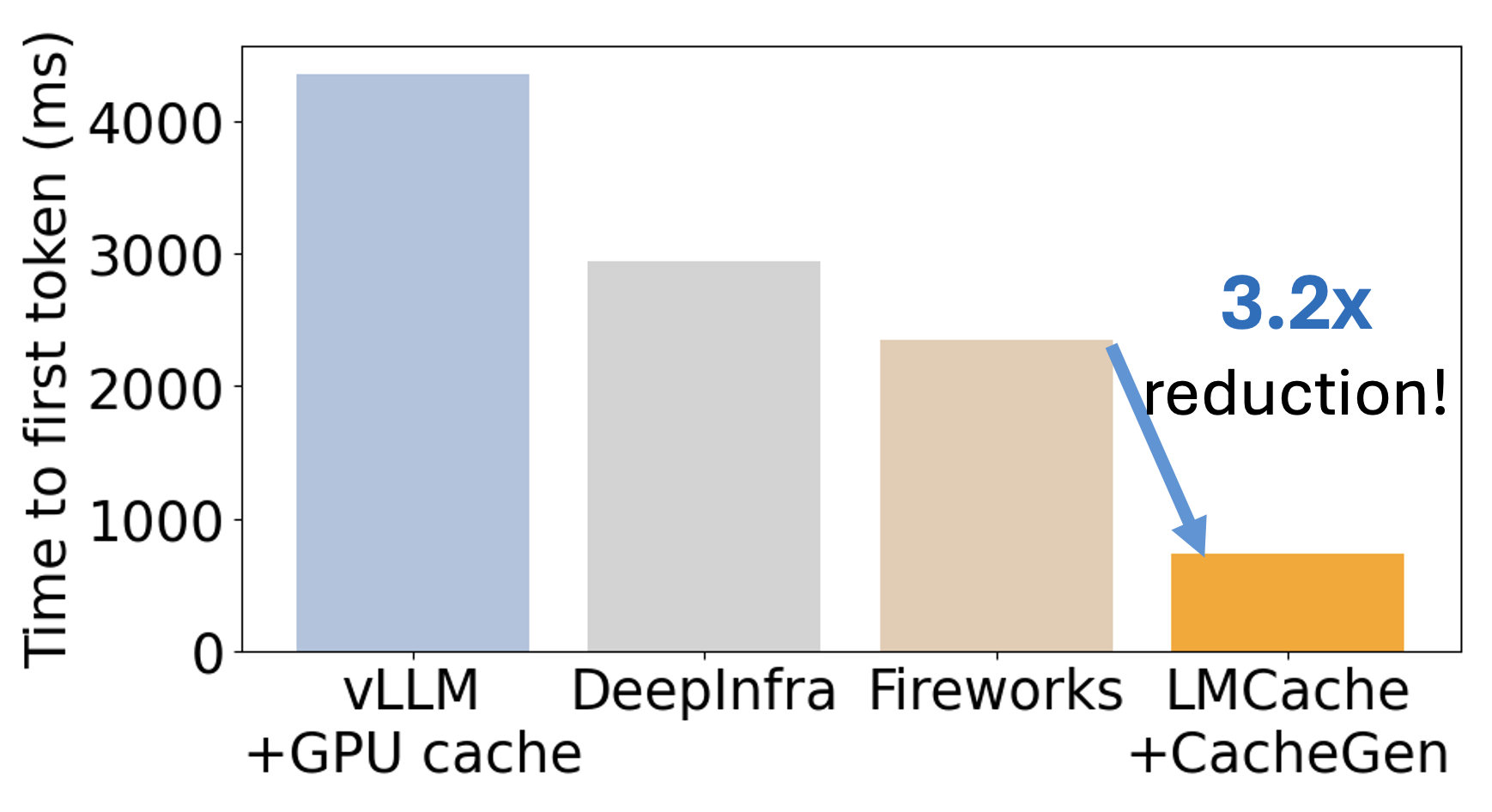
Key Results 📊
| System | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|
| LMCache + CacheGen | 737 | 47.7 |
| Naive vLLM | 4,355 | 247.6 |
| Fireworks | 2,353 | 664.7 |
| DeepInfra | 2,949 | 79.0 |
| Baseten | 113,239 | 174.9 |
Takeaway: CacheGen cuts Time-To-First-Token (TTFT) by up to 3× compared to other baselines, and reduces per-token latency, too.
How Does It Work?
- Compress: CacheGen encodes KV cache with custom quantization and residue coding—making files up to 3× smaller than quantized tensors.
- Decompress: Fast CUDA kernels restore the cache in milliseconds, right into GPU memory.
Quick Start 🛠️
uv pip install vllm
uv pip install lmcache
# Start cache server
lmcache_server localhost 65434
# Start vLLM+LMCache server (using CacheGen)
LMCACHE_CONFIG_FILE=example.yaml CUDA_VISIBLE_DEVICES=2 vllm serve meta-llama/Llama-3.1-8B-Instruct --gpu-memory-utilization 0.8 --port 8020 --kv-transfer-config '{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
example.yaml:
chunk_size: 2048
local_cpu: False
remote_url: "lm://localhost:65434"
remote_serde: "cachegen"
Citation
If you use CacheGen in your research, please cite our paper:
@misc{liu2024cachegenkvcachecompression,
title={CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving},
author={Yuhan Liu and Hanchen Li and Yihua Cheng and Siddhant Ray and Yuyang Huang and Qizheng Zhang and Kuntai Du and Jiayi Yao and Shan Lu and Ganesh Ananthanarayanan and Michael Maire and Henry Hoffmann and Ari Holtzman and Junchen Jiang},
year={2024},
eprint={2310.07240},
archivePrefix={arXiv},
primaryClass={cs.NI},
url={https://arxiv.org/abs/2310.07240},
}
Paper: CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving
Contact
- LMCache Github: https://github.com/LMCache/LMCache
- Chat with the Developers Interest Form
- LMCache slack
- vLLM Production-Stack channel
CacheGen: persistent, streaming context for fast, scalable LLMs—the LMCache Lab way! 🚀