Speeding Up LLM Inference: Beyond the Inference Engine
By Junchen Jiang, Hanchen Li, Jake Sonsini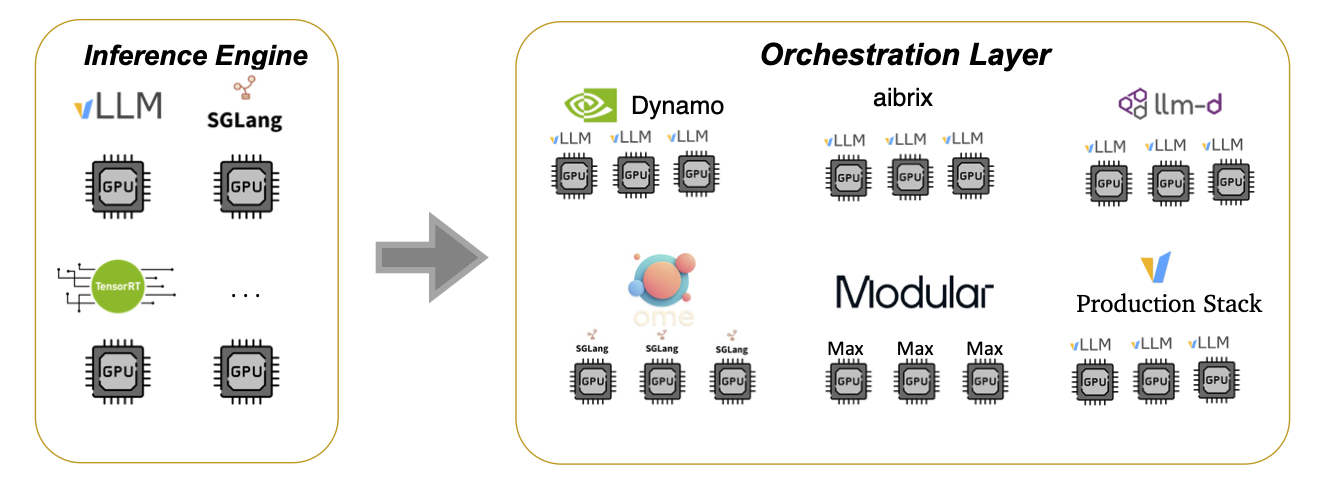
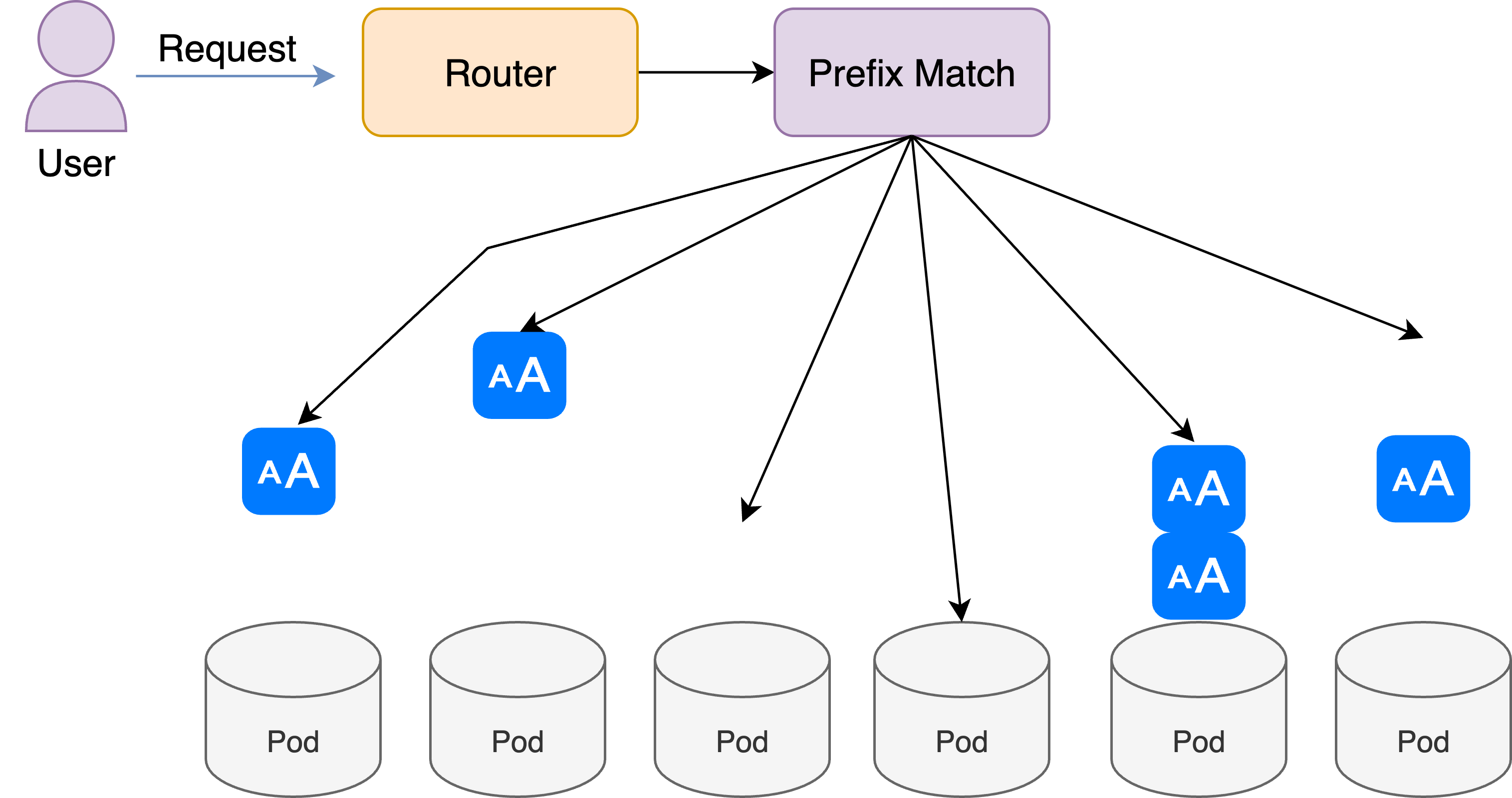
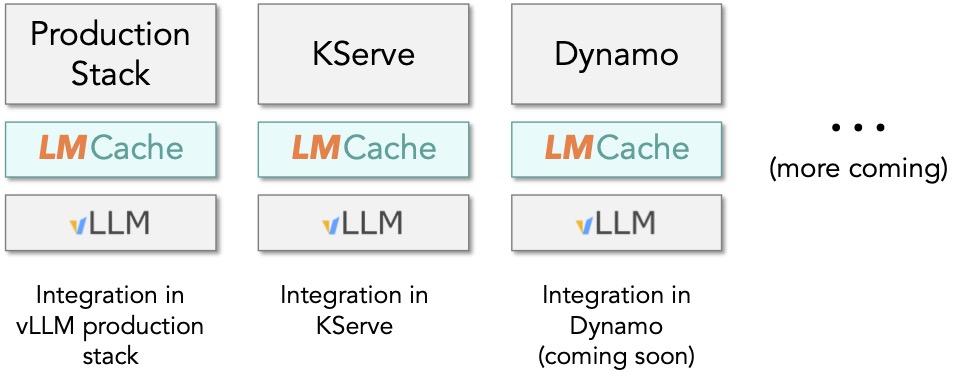
TL;DR: LLMs are rapidly becoming the dominant workload in enterprise AI. As more applications rely on real-time generation, inference performance — measured in speed, cost, and reliability — becomes the key bottleneck. Today, the industry focuses primarily on speeding up inference engines like vLLM, SGLang, and TensorRT. But in doing...
[Read More]