过去几个月里,Claude Code 悄然成为了普通开发者可以使用的最有趣且被广泛采用的真实世界智能体(Agentic)系统之一。
它不同于那些内部机制隐藏在 API 网关之后的纯云端智能体(如 Perplexity、Devin 或 Manus),也不像完全的开源智能体(如 Mini SWE Agent 或 Terminus 2)那样你可以部署源代码。Claude Code 以部分本地的方式运行——它有一个运行在本地机器上的开源 客户端仓库。这给了我们一个难得的机会:通过注入并拦截它发送的流量来进行逆向工程,查看每一个 LLM 调用、每一次中间的工具调用,以及智能体做出的每一个微小决策。
最近,我们使用 Claude Code 进行了一次微型的单次实验(从 SWE-bench_Verified 数据集中随机选择了一个任务),并将所有内容捕获到一个仅包含 LLM 输入和输出的原始日志文件中:claude_code_trace.jsonl。如果你将 这个追踪文件 粘贴到 可视化工具 中,你可以看到追踪的详细信息。
关键指标:
- 92 次 LLM 调用 (
#1-#92) - 消耗了 ~200 万个输入 token
- 总时长 13 分钟
- 92% 的前缀复用率
目标很简单:
如果给 Claude Code 一个小任务,幕后究竟发生了什么?
进行了哪些 LLM 调用?顺序如何?
上下文在哪里被复用?有多少提示词(Prompt)是稳定的前缀(已见内容),又有多少是增量内容(新内容)?
这就是我们要对该追踪记录进行的详细解读。
1. 当 Claude Code 运行一个简单任务时,“实际”发生了什么
作为一个产品,Claude Code 给人的感觉非常直观——你在编辑器中输入请求,它就会编辑文件或运行一些 bash 命令。但在底层,即使是一个简单的一步请求,也会分解成一个结构惊人的内部循环。
我们从 SWE-bench_Verified 数据集中随机选择了 一个任务 (#80)。问题背景是修复 django/django 仓库中 commit 2e0f04507b17362239ba49830d26fec504d46978 的一个问题。
问题陈述:
“JSONField 在 admin 中设为只读时显示不正确。
描述:JSONField 的值在 admin 中为只读时显示为字典。例如,
{"foo": "bar"}会显示为{'foo': 'bar'},这不是有效的 JSON。我认为修复方法是在
django.contrib.admin.utils.display_for_field中添加一个特殊情况,调用 JSONField 的prepare_value(而不是直接调用json.dumps,以处理InvalidJSONInput的情况)。”
这正是 Claude Code 收到的提示词。
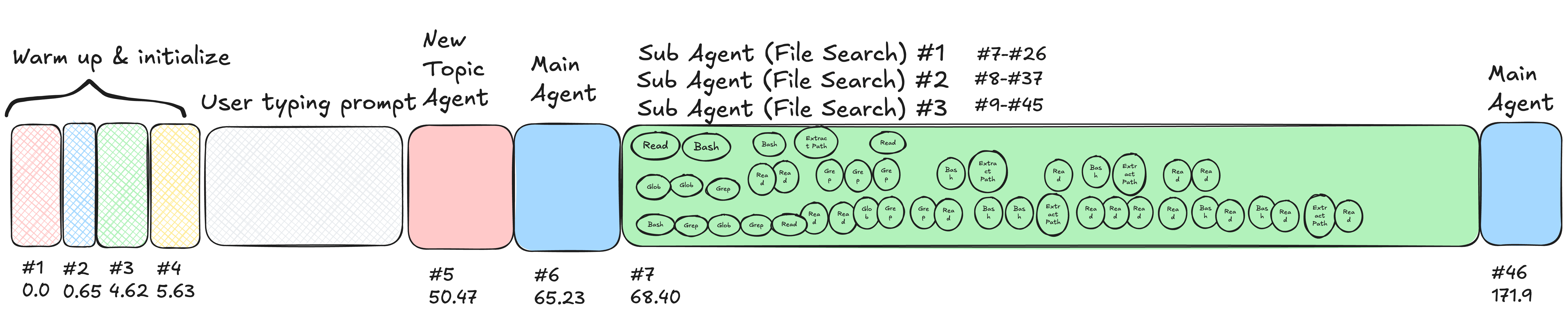
令人惊讶的是,在进行任何复杂的推理之前,Claude Code 在执行实际任务之前运行了几个“热身”步骤(追踪 ID #2, #3, #4)。热身步骤除了输入提示词外不做其他事情,目的是为了:
- 工具列表 (
#2) - 探索(Explore)子智能体 (
#3) - 规划(Plan)子智能体 (
#4)
热身步骤用于缓存目的——稍后当调用这些工具和子智能体时,将命中缓存,从而缩短响应时间。总结智能体(#1)和新主题智能体(#5)用于总结上下文并生成显示的新标题——就像 ChatGPT 侧边栏的工作方式一样。
主智能体(#6)带有一个巨大的系统提示词(System Prompt),包括 git 历史、状态、工具列表等。工具列表中的 18 个工具不仅能够使用像 Bash、Grep、Read、WebFetch、AskUserQuestion 等常规工具调用,还能够调用并将某些任务委托给子智能体,如:
- 探索(Explore)子智能体 (
#7) - 规划(Plan)子智能体 (
#46)
这些子智能体将从它们自己的工具列表中调用工具。
在主智能体(#6)之后,它立即调用了 探索(Explore)(也称为文件搜索智能体)子智能体(#7),该子智能体将调用其工具列表中的工具来探索代码库。它以一个不同的系统提示词开始,其主要目标是探索代码库:
你是 Claude Code,Anthropic 的官方 Claude CLI。你是 Claude Code 的文件搜索专家。你擅长彻底地浏览和探索代码库。
有趣的是,探索子智能体(#7)并不是 Claude Code 调用的唯一子智能体。相反,它并行调用了 3 个探索子智能体 来探索代码库,每个都有不同的目标:
- 探索 JSONField 实现(生命周期:
#7-#26) - 探索 admin display_for_field(生命周期:
#8-#37) - 探索只读字段渲染(生命周期:
#9-#45)
主智能体(#6)的上下文没有传递给子智能体,这有利于子智能体轻装上阵(fresh start)。每个探索子智能体可以并行调用 1-3 个工具,这些工具来自探索子智能体的工具列表——这是主智能体工具列表的一个子集(10/18)。
这里使用了 ReAct 机制:探索子智能体将调用一个工具,然后根据工具输出进行观察,并调用另一个工具进一步探索代码库,直到它认为已经探索得足够充分。
最后,在最慢的探索子智能体于步骤 #45 完成探索后,在步骤 #46, 主智能体将所有 3 个探索子智能体的发现(总结)追加到上下文中,然后调用规划子智能体(#47)来规划修复方案。

与探索智能体类似,规划智能体(#47)也有一个不同的系统提示词,其主要目标是规划修复方案:
你是 Claude Code,Anthropic 的官方 Claude CLI。你是 Claude Code 的软件架构师和规划专家。你的角色是探索代码库并设计实施计划。
规划智能体没有携带主智能体或探索子智能体的所有上下文,这有利于规划智能体拥有一个全新的开始。相反,它只包含探索子智能体发现的总结。工具箱是主智能体工具列表的一个子集(10/18)。规划智能体的目标是设计一个实施计划,该计划需要:
请设计一个实施计划:
- 确定 display_for_field 需要的确切更改
- 考虑我们需要从模型字段实例化表单字段,还是有更好的方法
- 识别任何边缘情况或潜在问题
- 鉴于 Django 的架构,推荐最佳方法

同样,规划智能体也遵循 ReAct 模式,并在 #47 到 #72 之间循环调用工具,其中上下文从 11,552 tokens 累积到 38,819 tokens。在制定好计划后(详见 #72),规划智能体将带着计划返回给主智能体(#73)。
然后,主智能体将调用一系列工具来:
- 审查计划 (
#73) - 询问用户以进行澄清 (
#74) - 将计划写入 markdown 文件 (
#75)
最后,主智能体将退出规划模式(#76)并进入执行模式(#77),在交互式地询问用户批准计划后执行该计划(#76-#77)。
执行阶段(#77-#91)仍然遵循 ReAct 模式。主智能体将使用计划 markdown 文件作为待办事项列表(todo list):
- 将 json import 添加到
utils.py- 将 JSONField 处理添加到
display_for_field()- 将测试添加到
test_admin_utils.py- 运行测试以验证
在执行一些工具调用以读取或编辑文件后,它将划掉计划 markdown 文件中的待办事项。一旦所有待办事项都被划掉,主智能体将以结束语(#92)结束。
在此阶段,还有一些其他子智能体被调用——例如,提取 Bash 命令子智能体(#93),该子智能体只有一个 one-shot 提示词模板,用于提取 bash 命令,以避免在没有用户确认的情况下意外运行像 rm 这样的危险命令。
这就是 Claude Code 追踪的全貌图解:
2. 秘密模式:Claude Code 是一台前缀复用机器
在我们的追踪分析中,有一个现象非常一致,值得单独列出一节:
Claude Code 的提示词极其依赖前缀。
前缀复用意味着提示词前缀的一部分在之前的提示词前缀中已经出现过。在所有阶段中,提示词复用率极高:92%。对于基于 ReAct 的子智能体循环,这个比例甚至更高。如果我们在特定部分运行前缀长度分析:
| 追踪 ID | 总 Token 数 | 共享前缀 % | 备注 |
|---|---|---|---|
#1-#6 | 47,177 | 0.22% | 热身和初始阶段 |
#7-#45 | 546,104 | 92.06% | 探索子智能体阶段 |
#47-#72 | 528,286 | 93.23% | 规划子智能体阶段 |
#73-#92 | 827,411 | 97.83% | 主智能体执行阶段 |
这意味着什么?Claude Code 的架构实际上自我优化了 KV 缓存(KV cache)的复用,即使没有显式地尝试这样做。
3. 什么是前缀缓存,我为什么要关心?
大型语言模型推理的核心在于 KV 缓存(键值缓存)——一种存储先前处理过的 token 的中间注意力计算结果的机制。在自回归生成过程中,每个新 token 都需要关注所有先前的 token,这需要昂贵的矩阵乘法。KV 缓存存储了为早期 token 计算的键(Key)和值(Value)矩阵,因此不需要为每个新 token 重新计算它们。
前缀缓存(Prefix caching)利用了这一点,它识别出当多个请求共享相同的提示词前缀(如系统指令或文档上下文)时,它们的 KV 缓存计算是相同的,可以跨请求复用。
主要的 LLM 提供商已将其转化为显著的成本节约:
- OpenAI 的 Prompt Caching 自动处理前缀缓存——它透明地检测长度超过 1,024 个 token 的公共前缀并进行缓存,为缓存的输入 token 提供 90% 的折扣(例如,GPT-4o 从每百万 token $2.50 降至 $1.25)
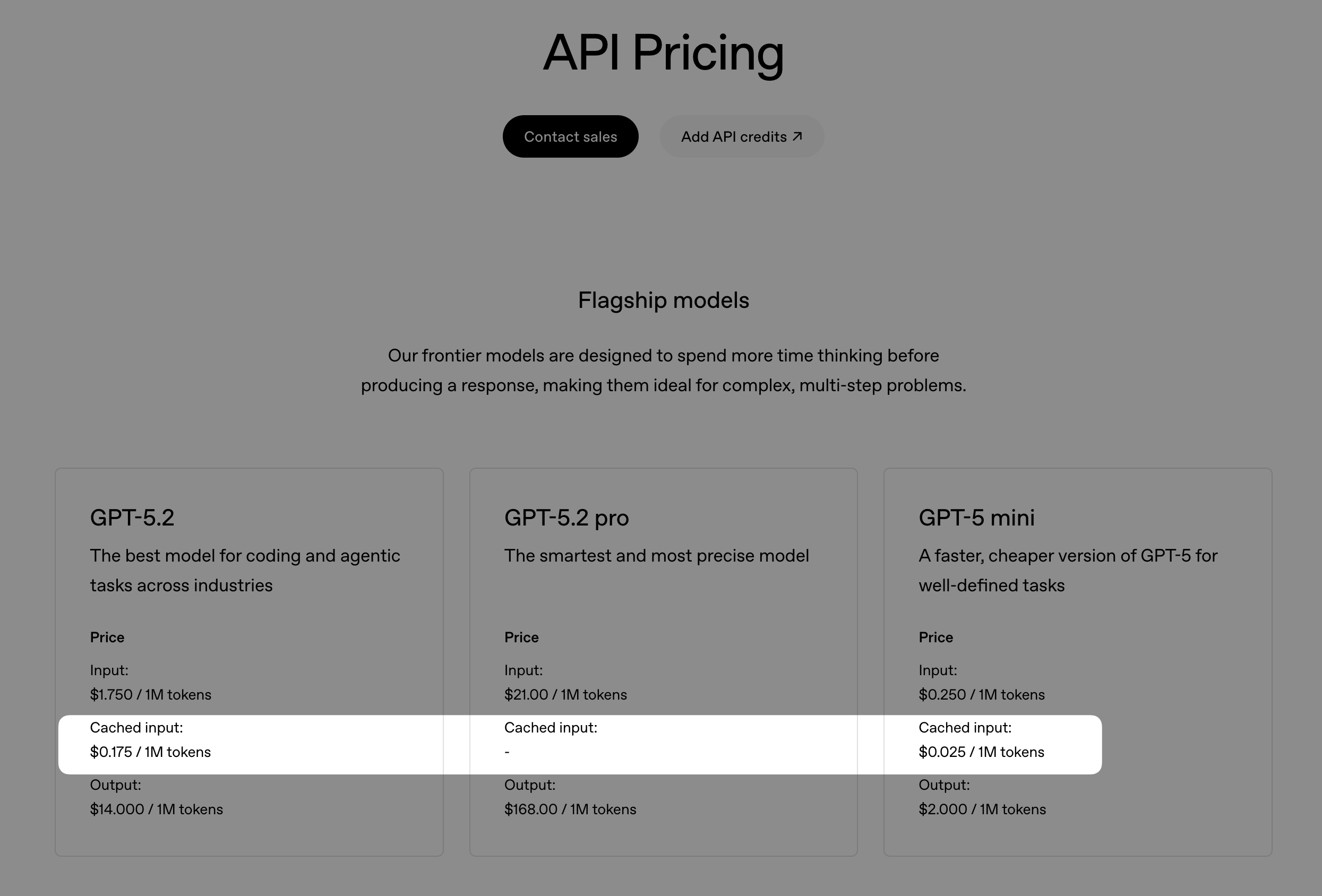
- Anthropic 的缓存命中定价 给予开发者明确的控制权,使用特殊的
cache_control标记来决定缓存哪些提示词块,收取稍高的缓存写入成本(5 分钟缓存为基础价格的 1.25 倍,1 小时缓存为 2 倍),但为缓存读取提供同样的 90% 折扣(Claude Sonnet 3.5:缓存读取为每百万 token $0.30,而基础输入为 $3.00),允许针对复杂的多轮对话或重文档工作流进行精细优化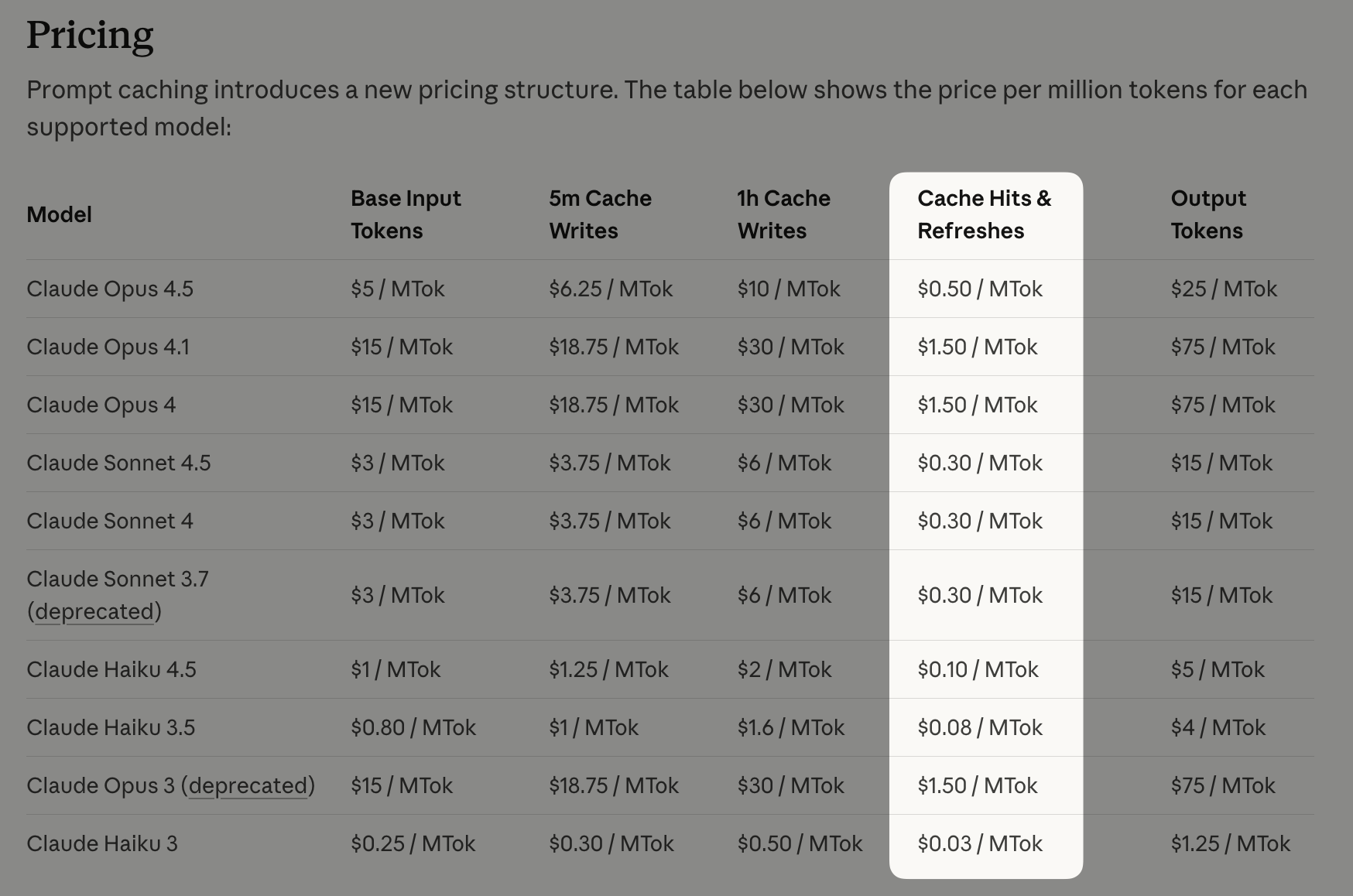
结合 Claude Code 的 92% 前缀复用模式来看:处理 200 万个输入 token(我们要实验的消耗)如果不使用缓存将花费 $6.00(2M × $3/MTok),但使用前缀缓存,成本仅为 $1.152(1.84M 缓存命中 × $0.30/MTok + 0.16M 缓存写入 × $3.75/MTok)——仅在一个简单任务上就节省了 $4.85(减少 81%)。
开源推理引擎也接受了这种范式:
- vLLM 的自动前缀缓存 使用其 PagedAttention 机制透明地缓存共享前缀。
- SGLang 的 RadixAttention 采用基数树(radix tree)数据结构来有效地匹配和复用跨请求的最长公共前缀。
- LMCache 通过在多个节点之间池化缓存存储,进一步扩展了分布式 KV 缓存,以最大限度地扩大规模复用。
除了节省成本外,前缀缓存命中还显著降低了 TTFT(首 token 时间)——因为模型可以跳过重新计算整个前缀,只处理唯一的后缀,共享上下文的后续请求的延迟可以下降 5-10 倍,使对话智能体和基于文档的应用程序响应更加迅速。
4. 我们从这个微小的追踪中学到了什么
尽管任务微不足道,但追踪揭示了许多关于 Claude Code 作为系统的信息:
主系统提示词(System Prompt)非常庞大
- 它包含:完整的 git 仓库状态和历史 + 完整的工具规范(主智能体 18 个工具)+ 最后是执行阶段的指令。
- 仅提示词本身在没有对话历史的情况下就超过 20,000+ tokens。
Claude Code 是围绕专用子智能体构建的
- 子智能体仅接收特定角色的上下文,减少了臃肿。
- 上下文的分离允许主智能体仅基于子智能体的总结响应来运行。
利用并行执行来最大化探索效率
- 子智能体在各自的 ReAct 循环下并行生成,具有不同的搜索目标。
- 这种分离允许清晰的上下文和专注的子任务,均匀地分配上下文。
- 工具调用也并行运行以获得同样的好处。
“热身”调用在实际工作开始前填充缓存
- 它们将工具规范加载到缓存中,预热子智能体系统提示词,并建立稳定的前缀基线。
- 这些调用极大地加速了随后的子智能体调用。
Claude 非常适合 KV 缓存复用
- Claude 达到了高达 92% 的整体前缀复用率,非常适合 KV 缓存复用优化。
- 在一个简单的任务上就显著节省了 $4.85(减少 81%) 的成本。
交互式规划提高了透明度
- 给予用户控制权,决定将进行哪些更改。
- 创建一个自然的断点,提示用户批准。
- 响应允许系统创建一个更精细的可执行待办事项列表,改善工作流程。
5. 超越前缀缓存:我们能做得更好吗?
最近,有一些有趣的研究论文试图提高非前缀缓存的效率,例如 CacheBlend,即使在非前缀(子字符串)缓存上也可以进行优化。
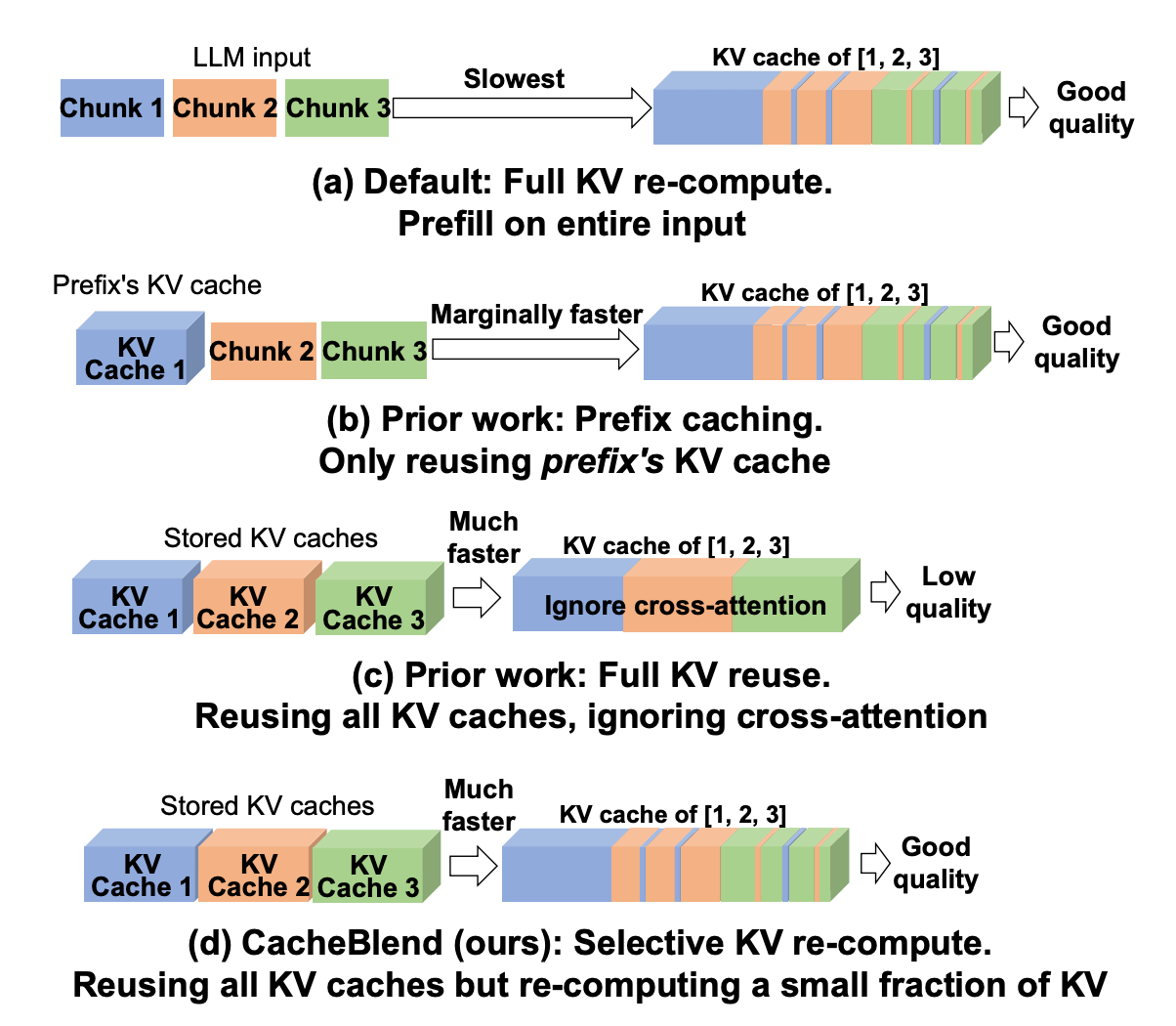
在我们的追踪中,我们可以看到子智能体的工具列表是主智能体工具列表的子集,这意味着子智能体可以复用主智能体的工具列表描述。这是如何提高非前缀缓存效率的一个很好的例子。
我们追踪中的另一种情况是,如果同一个文件被读取多次,文件内容可以被缓存和复用,即使文件内容不是前缀。当文件内容很大且文件被多次读取时,这将非常有帮助。
发表评论